数据规范
古语有云: “兵马未动, 粮草先行”。在人工智能时代, 当我们面对各种各样的问题场景, 选对算法对于成功建立模型十分的重要。此外, 向算法注入正确合规的数据也很重要。在本章, 为了可以快速且正确地掌握并使用HyperTS, 我们将详细地介绍HyperTS在各类时序任务中所需的数据规范格式。
时序预测任务
预测数据格式
在预测任务中, 输入数据应该是一个含有时间列(TimeStamp)和变量列的 pandas.DataFrame 格式的二维数据表, 形式如下所示:
time_col var_col_0 var_col_1 var_col_2 ... var_col_n
xxxx-xx-xx xx:xx:xx x x x x
xxxx-xx-xx xx:xx:xx x x x -
xxxx-xx-xx xx:xx:xx x x x x
xxxx-xx-xx xx:xx:xx - x x x
xxxx-xx-xx xx:xx:xx x x x x
xxxx-xx-xx xx:xx:xx x - x x
xxxx-xx-xx xx:xx:xx x - x x
xxxx-xx-xx xx:xx:xx x x - x
xxxx-xx-xx xx:xx:xx x x x x
xxxx-xx-xx xx:xx:xx x x - x
xxxx-xx-xx xx:xx:xx - - - -
xxxx-xx-xx xx:xx:xx x x x x
- - - - -
xxxx-xx-xx xx:xx:xx x x x x
其中, xxxx-xx-xx xx:xx:xx表示时间 (理想情况下, YYYY-MM-DD 格式的日期或者 YYYY-MM-DD HH:MM:SS 格式的时间戳), (x)表示某个时刻某个变量值, (-)表示缺失值。
备注
在预测任务中的数据中, HyperTS期待也必须含有时间列, 列名称不作规范, 无论是ds, ts, timestamp, TimeStamp还是其他。
时间列可以具有
pandas.to_datetime可以识别的任何格式。时间可以是无序的, HyperTS可以自动转化为有序数列。
输入数据的频率满足多种时间粒度, 秒(S)、分钟(T)、小时(H)、日(D)、周(W)、月(M)、每年(Y)等等。
输入数据允许存在缺失值, 缺失点与缺失时间片段, HyperTS将会在数据预处理过程被填充。
输入数据允许存在重复行, 重复的时间片段, HyperTS将会在被在数据预处理过程被裁剪。
当所解决任务中有辅助建模的数据, 我们称之为协变量, 它仅需跟附在上述数据的DataFrame中, 形式如下所示:
time_col var_col_0 var_col_1 ... var_col_n covar_col_0 covar_col_1 ... covar_col_m
xxxx-xx-xx xx:xx:xx x x x x x x
xxxx-xx-xx xx:xx:xx x x - x x x
xxxx-xx-xx xx:xx:xx x x x x - x
xxxx-xx-xx xx:xx:xx - x x x x -
xxxx-xx-xx xx:xx:xx x x x x x x
xxxx-xx-xx xx:xx:xx x - x x x x
xxxx-xx-xx xx:xx:xx x - x x x x
xxxx-xx-xx xx:xx:xx x x x x - x
xxxx-xx-xx xx:xx:xx x x x x x x
xxxx-xx-xx xx:xx:xx x x x x x x
xxxx-xx-xx xx:xx:xx - - - x x x
xxxx-xx-xx xx:xx:xx x x x x x x
- - - - - - -
xxxx-xx-xx xx:xx:xx x x x x x x
其中, covar_col_i (i=1, 2, .., m)表示协变量。
备注
协变量可以是数值型(连续变量)也可以是类别型(离散变量)。
协变量也允许存在缺失值和重复值, 不需要自己处理。
预测数据示例
没有协变量
import numpy as np
import pandas as pd
size=5
df_no_covariate = pd.DataFrame({
'timestamp': pd.date_range(start='2022-02-01', periods=5, freq='H'),
'val_0': np.random.normal(size=size),
'val_1': [0.5, 0.2, np.nan, 0.9, 0.0],
'val_2': np.random.normal(size=size),
})
df_no_covariate
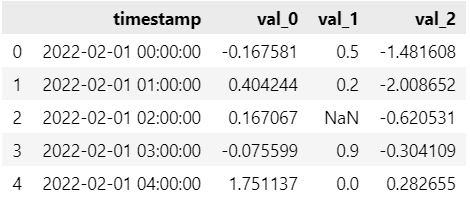
我们随机生成一个不含协变量的时序预测数据集, 信息解析如下:
时间列名称: ‘timestamp’;
目标列名称: ‘var_0’, ‘var_1’, ‘var_2’;
时间频率: ‘H’;
含有部分缺失值;
多变量预测。
有协变量
df_with_covariate = pd.DataFrame({
'timestamp': pd.date_range(start='2022-02-01', periods=size, freq='D'),
'val_0': np.random.normal(size=size),
'val_1': [12, 52, 34, np.nan, 100],
'val_2': [0.5, 0.2, np.nan, 0.9, 0.0],
'covar_0': [0.2, 0.4, 0.2, 0.7, 0.1],
'covar_1': ['a', 'a', 'b', 'b', 'b'],
'covar_2': [1, 2, 2, None, 3],
})
df_with_covariate
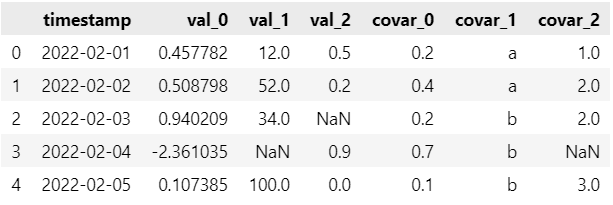
我们随机生成一个含有协变量的时序预测数据集, 信息解析如下:
时间列名称: ‘timestamp’;
目标列名称: ‘var_0’, ‘var_1’, ‘var_2’;
协变量列名称: ‘covar_0’, ‘covar_1’, ‘covar_2’;(新增)
时间频率: ‘D’;
含有部分缺失值;
多变量预测。
时序分类及回归任务
分类及回归数据格式
在分类及回归任务中, 它们与预测任务的数据形式有所差别。具体表现在输入数据的形式为含有目标列(target)及特征列的嵌套(nested) pandas DataFrame 格式的二维数据表, 形式如下所示:
var_col_0 var_col_1 var_col_2 ... var_col_n target
x, x, x, ..., x x, x, x, ..., x x, x, x, ..., x x, x, x, ..., x y
x, x, x, ..., x x, x, x, ..., x x, x, x, ..., x x, x, x, ..., x y
x, x, x, ..., x x, x, x, ..., x x, x, x, ..., x x, x, x, ..., x y
x, x, x, ..., x x, x, x, ..., x x, x, x, ..., x x, x, x, ..., x y
x, x, x, ..., x x, x, x, ..., x x, x, x, ..., x x, x, x, ..., x y
x, x, x, ..., x x, x, x, ..., x x, x, x, ..., x x, x, x, ..., x y
x, x, x, ..., x x, x, x, ..., x x, x, x, ..., x x, x, x, ..., x y
x, x, x, ..., x x, x, x, ..., x x, x, x, ..., x x, x, x, ..., x y
x, x, x, ..., x x, x, x, ..., x x, x, x, ..., x x, x, x, ..., x y
其中, x, x, x, …, x表示某个样本在len(x, x, x, …, x)长度的时间片段某变量随时间的波动情况。(x)表示某个时刻某个变量值。(y)表示该行样本的标签, 离散值(分类)或者连续值(回归)。
备注
分类或者回归任务是针对一个样本判断其行为, 故与预测任务的数据形式不同, 预测数据每一行表示一个时间点各个变量的值, 而分类或预测数据每一行表示一个样本, 而每一个cell, 即 x, x, x, …, x 表示某样本在 len(x, x, x, …, x) 长度的时间片段某变量随时间波动的情况。每个样本根据各个变量的序列行为判别
target的类别(分类)或者数值(回归)。直觉上,
pandas DadaFrame是一二维数据表, 每一个cell储存一个数值, 现在我们储存一个序列, 从而将三维数据嵌套在二维数据表中, 这也是我们称之为 nested DataFrame 的原因。分类或回归任务的目标是判别每一个样本的类别或者行为, 故数据的走势是关键特质, 所以为了简单起见, 我们在存储时省略去TimeStamp的信息。
分类数据示例
import numpy as np
import pandas as pd
size=10
df = pd.DataFrame({
'var_0': [pd.Series(np.random.normal(size=size)), pd.Series(np.random.normal(size=size)),
pd.Series(np.random.normal(size=size)), pd.Series(np.random.normal(size=size)),
pd.Series(np.random.normal(size=size)), pd.Series(np.random.normal(size=size))],
'var_1': [pd.Series(np.random.normal(size=size)), pd.Series(np.random.normal(size=size)),
pd.Series(np.random.normal(size=size)), pd.Series(np.random.normal(size=size)),
pd.Series(np.random.normal(size=size)), pd.Series(np.random.normal(size=size))],
'var_2': [pd.Series(np.random.normal(size=size)), pd.Series(np.random.normal(size=size)),
pd.Series(np.random.normal(size=size)), pd.Series(np.random.normal(size=size)),
pd.Series(np.random.normal(size=size)), pd.Series(np.random.normal(size=size))],
'y': [0, 0, 1, 1, 2, 2],
})
df

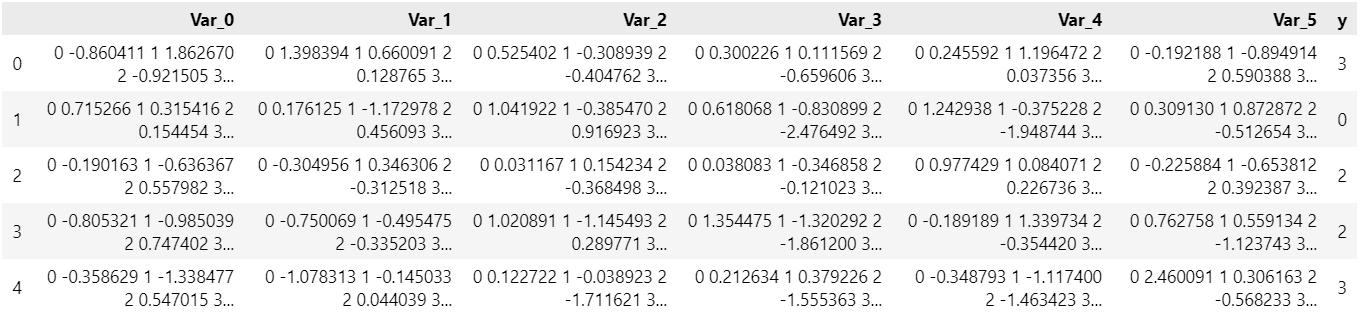
我们随机生成一个时序分类的数据集, 信息解析如下:
目标变量名称:’y’;
特征变量名称:’var_0’, ‘var_1’, ‘var_2’;
多变量分类。
嵌套Dataframe转换
当拿到的原始数据是 numpy.array 形式时, 我们如何将其转化为嵌套的 pandas.DataFrame 数据呢? 例如如下数据:
import numpy as np
nb_samples = 100
series_length = 72
nb_variables = 6
nb_classes = 4
X = np.random.normal(size=nb_samples*series_length*nb_variables).reshape(nb_samples, series_length, nb_variables)
y = np.random.randint(low=0, high=nb_classes, size=nb_samples)
print(X)
array([[[ 0.57815678, 0.41459846, -0.50473205, -1.99750872,
1.4631261 , -1.93345998],
[ 0.80831576, -0.21562245, 1.29258974, 0.78233567,
0.87576927, -1.34082721],
[ 0.41409349, 0.40804883, 0.96354344, 1.5678011 ,
0.60987622, 0.28618276],
...,
[-0.09893226, -0.47034969, -0.2822979 , 1.41712479,
-0.55125917, 1.38645133],
[ 0.86447489, -1.44334104, 0.38009615, 1.86328252,
0.39575692, -1.50915368],
[ 0.49571136, 0.60916544, 1.34735049, 1.14492395,
-1.01143839, 0.06649033]],
...
print(y)
array([0, 1, 0, 1, 1, 1, 3, 0, 2, 2, 0, 0, 3, 0, 2, 1, 3, 0, 1, 3, 3, 1,
1, 1, 1, 2, 3, 3, 3, 3, 3, 3, 1, 2, 1, 2, 1, 3, 1, 3, 0, 1, 1, 2,
3, 3, 2, 2, 3, 1, 2, 0, 0, 0, 0, 3, 1, 3, 3, 0, 3, 3, 3, 1, 2, 2,
2, 1, 2, 0, 0, 1, 3, 1, 1, 3, 2, 1, 1, 3, 2, 1, 2, 2, 3, 0, 2, 2,
3, 1, 0, 2, 2, 1, 1, 1, 0, 0, 1, 1])
通过以上信息可知, 该数据包含了100个样本, 每个样本有6个变量, 而每个变量是长度为72的时间序列。y共有4个类别。
面对这样的情况, HyperTS为您提供了相关变换的工具函数 from_3d_array_to_nested_df:
import pandas as pd
from hyperts.toolbox import from_3d_array_to_nested_df
df_X = from_3d_array_to_nested_df(data=X)
df_y = pd.DataFrame({'y': y})
df = pd.concat([df_X, df_y], axis=1)
df.head()
时序异常检测任务
与预测任务相似,输入数据应该是一个含有时间列(TimeStamp)和变量列的```pandas DataFrame```格式的二维数据表, 其应该包含时间戳列(time_col),一个或多个变量列(var_col_0, var_col_1, var_col_2,… var_col_n),如果有协变量,也可包含一个或多个协变量(covar_col_0, covar_col_1, covar_col_2,… covar_col_m),形式如下所示:
xxxx-xx-xx xx:xx:xx x x x x x x xxxx-xx-xx xx:xx:xx x x - x x x xxxx-xx-xx xx:xx:xx x x x x - x xxxx-xx-xx xx:xx:xx - x x x x - xxxx-xx-xx xx:xx:xx x x x x x x xxxx-xx-xx xx:xx:xx x - x x x x xxxx-xx-xx xx:xx:xx x - x x x x xxxx-xx-xx xx:xx:xx x x x x - x xxxx-xx-xx xx:xx:xx x x x x x x xxxx-xx-xx xx:xx:xx x x x x x x xxxx-xx-xx xx:xx:xx - - - x x x xxxx-xx-xx xx:xx:xx x x x x x x
xxxx-xx-xx xx:xx:xx x x x x x x ```
此外,以上数据也可以包含 真实标签,这将有助于模型选择和超参数搜索过程。形式如下所示:
time_col var_col_0 var_col_1 ... var_col_n covar_col_0 covar_col_1 ... covar_col_m anomaly
xxxx-xx-xx xx:xx:xx x x x x x x 1
xxxx-xx-xx xx:xx:xx x x - x x x 0
xxxx-xx-xx xx:xx:xx x x x x - x 0
xxxx-xx-xx xx:xx:xx - x x x x - 1
xxxx-xx-xx xx:xx:xx x x x x x x 0
xxxx-xx-xx xx:xx:xx x - x x x x 0
xxxx-xx-xx xx:xx:xx x - x x x x 0
xxxx-xx-xx xx:xx:xx x x x x - x 0
xxxx-xx-xx xx:xx:xx x x x x x x 1
xxxx-xx-xx xx:xx:xx x x x x x x 0
xxxx-xx-xx xx:xx:xx - - - x x x 0
xxxx-xx-xx xx:xx:xx x x x x x x 0
- - - - - - - 1
xxxx-xx-xx xx:xx:xx x x x x x x 0
其中, anomaly 是异常标签列.
备注
当训练数据包含真实标签时,优化评估过程将采用真实标签。否则,将应用伪标签技术。