快速开始
HyperTS是 DataCanvas Automatic Toolkit (DAT) 工具链中, 依托 Hypernets 衍生的关于时间序列的全Pipeline的自动化工具包。它遵循了 make_expriment 的使用习惯(类似于 HyperGBM 的API, 一个针对于结构化表格数据的AutoML工具), 也符合 scikit-learn 中model API的使用规范。我们可以创造一个 make_expriment, run 之后获得pipeline_model, 即一个最终优化完毕的estimator, 然后使用它的 predict, evaluate, plot 去分析未知的数据。
通过 make_experiment 训练模型的基本步骤如下图所示:

HyperTS可以被用来解决时序预测、分类及回归任务, 它们公用统一的API。接下来, 我们将分为快速演示关于时序预测与分类任务的使用方法。
准备数据
可以根据实际业务情况通过pandas加载数据, 得到用于模型训练的DataFrame, 本例将加载HyperTS内置的数据集。
from hyperts.datasets import load_network_traffic
from sklearn.model_selection import train_test_split
对于划分训练集和测试集, 由于数据存在时间上的先后顺序, 因此为防止信息泄露, 我们从整体数据集的后边切分一部分, 故 shuffle=False。
df = load_network_traffic()
train_data, test_data = train_test_split(df, test_size=168, shuffle=False)
df.head()
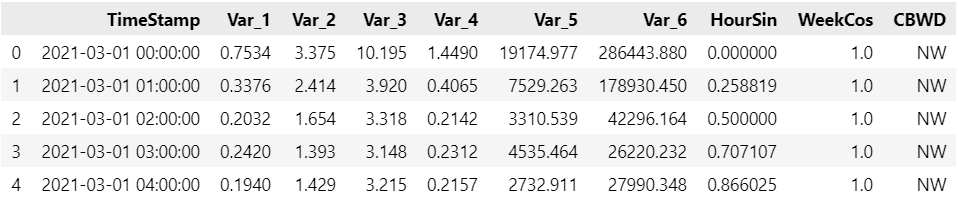
该数据集的一些基本信息具体如下:
时间列名称: ‘TimeStamp’;
目标列名称: [‘Var_1’, ‘Var_2’, ‘Var_3’, ‘Var_4’, ‘Var_5’, ‘Var_6’];
协变量列名称: [‘HourSin’, ‘WeekCos’, ‘CBWD’];
时间频率: ‘H’。
小技巧
如果您对HyperTS的数据格式不了解或者存有疑惑, 请参看 数据规范 。
创建实验并训练
我们通过 make_experiment 创建实验, 然后调用 run() 方法来执行实验去搜索一个时序模型。
from hyperts import make_experiment
experiment = make_experiment(train_data=train_data.copy(),
task='forecast',
timestamp='TimeStamp',
covariables=['HourSin', 'WeekCos', 'CBWD'])
model = experiment.run()
其中, model 就是本次 run() 搜索并训练所得到的最优的模型。
备注
在预测任务中, 我们必须向 make_experiment 传入参数 timestamp 列名。如果存在协变量, 也需要传入 covariables 列名。因此, 在本案例中, 我们需要向 make_experiment 传入以下参数:
时序预测任务, 即
task='forecast';数据集的时间列名称, 即
timestamp='TimeStamp';数据集中协变量列的名称, 即
covariables=['HourSin', 'WeekCos', 'CBWD'];
小技巧
如果想要获得强大的性能表现, 还可以修改其他默认的参数, 具体可以参考 高级应用。
未知数据预测
对test data切分X与y, 调用 predict() 方法执行结果预测。
X_test, y_test = model.split_X_y(test_data.copy())
forecast = model.predict(X_test)
forecast.head()

结果评估
调用 evaluate() 方法执行结果评估, 便可以观测到各个评估指标下的得分情况。
这里会返回一些默认的指标评分, 如果想观测指定指标的评分, 可以设置参数 metrics, 例如metrics=[‘mae’, ‘mse’, mape_func]。
其中, mape_func可以是自定义的评估函数或者来自于sklearn的评估函数。
results = model.evaluate(y_true=y_test, y_pred=forecast)
results.head()

可视化
调用 plot() 方法可视化, 观测预测曲线, 并与实际的曲线做对比分析。
model.plot(forecast=forecast, actual=test_data, var_id='Var_3', interactive=False)
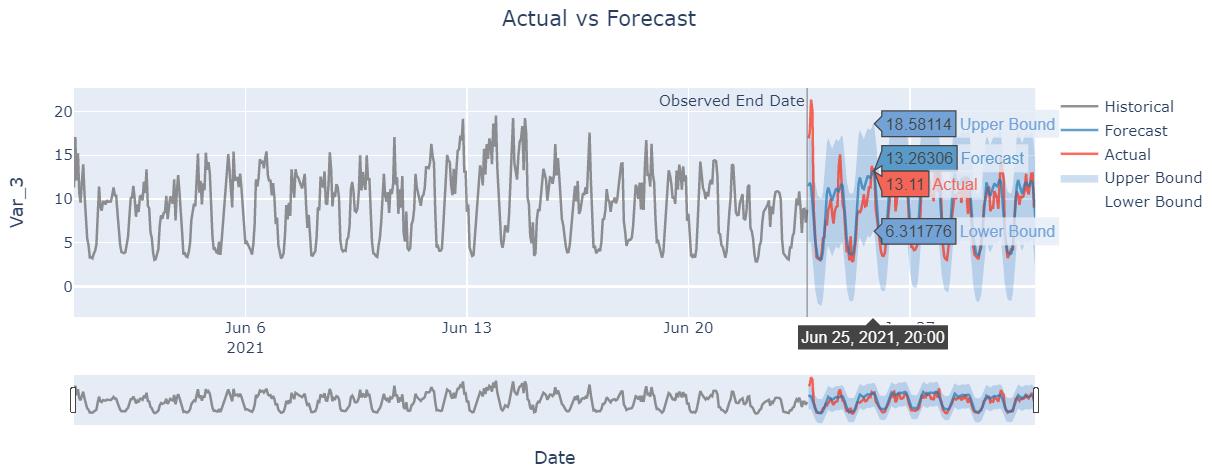
备注
这里会显示某一个变量的预测曲线, 默认为第一个目标变量;
如果为多变量预测, 想要观测其他的变量曲线变化的情况, 可以修改参数var_id, 例如:
var_id=2或者var_id='Var_3';plot可支持交互式可视化通过设置
interactive=False(默认交互, 需安装plotly);绘制更长期的历史信息, 设置参数
history=sub_train_data;当
actual=None(默认), 则只绘制预测曲线;当
show_forecast_interval=True(默认), 则利用贝叶斯推断预测置信区间.
小技巧
预测曲线由plotly工具绘制时, 通过点击可以交互式观测每个时刻的数值信息。
保存模型
使用 save() 去保存训练好的模型.
model.save(model_file="./xxx/xxx/models")
此外,也可以采用如下保存模型方式:
from hyperts.utils.models import save_model
save_model(model=model, model_file="./xxx/xxx/models")
加载模型
使用 load_model() 去加载已保存的模型.
from hyperts.utils.models import load_model
pipeline_model = load_model(model_file="./xxx/xxx/models/dl_models")